[AINews] The Core Skills of AI Engineering • ButtondownTwitterTwitter
Chapters
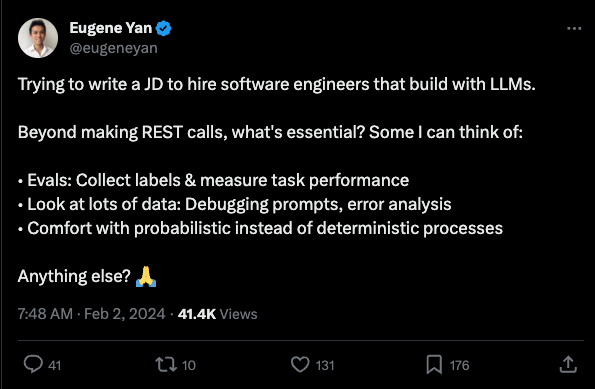
Discord Discussions on AI Engineering Skills
Nous Research AI Discord Summary
Alignment Lab AI Discord
LAION Research Insights
ML Library in an HPC Environment like LUMI
LM Studio General Discussions
HuggingFace Reading Group
Discord Communities Highlights
Troubleshooting CUDA and ImportError in Coding
Newsletter and Social Networks Links
Discord Discussions on AI Engineering Skills
The section provides a detailed summary of discussions from Discord communities like Latent Space, LAION, and Eleuther on various topics related to AI engineering skills and advancements. The conversations cover a wide range of subjects such as the evolving job roles of AI engineers, techniques for model training, model architectures, activation functions, legal complexities, knowledge distillation, and Monte Carlo Tree Search challenges. These discussions reflect the active and diverse learning initiatives, community growth activities, resource sharing, and concerns over tools reliance within the AI engineering communities.
Nous Research AI Discord Summary
LLaVA-1.6 Surpasses Gemini Pro:
A YouTube video demonstration suggests that LLaVA-1.6, with features like enhanced reasoning, OCR, and world knowledge, outperforms Gemini Pro on several benchmarks. Results and further details can be found on the LLaVA blog.
Hugging Face Introduces MiniCPM:
A new model, MiniCPM, showcased on Hugging Face, has sparked interest due to its potential and performance, with discussions comparing it to other models like Mistral and awaiting fine-tuning results.
ResNet Growth Techniques Applied to LLMs:
Discussions have surfaced around the application of "growing" techniques, successful with ResNet classifiers and ProGANs, to LLMs, evidenced by Apple's Matroyshka Diffusion model. The new Miqu model's entry on the Open LLM Leaderboard with notable scores leads to mixed reactions.
Quantization's Impact on AI Model Performance:
Conversations around miqu-70b bring up the potential effects of quantization on model performance aspects such as spelling accuracy, provoking thoughts on whether quantized models should be standard on certain platforms.
The Ongoing Pursuit for Optimized Tokenization:
The engineering community has discussions around multilingual tokenizers, with a 32000-token vocabulary potentially limiting models like LLaMA/mistral. Efforts to adapt LLaMA models for specific languages, such as VinaLLaMA for Vietnamese and Alpaca for Chinese, indicate progress in model internationalization.
Alignment Lab AI Discord
Daydream Nation Joins the Chat:
User @daydream.nation joined the [Alignment Lab AI ▷ #general-chat] and mentioned the team's project going public, expressing regret for not having participated in it yet, and speculated on the intent to test human interaction on a larger scale in the context of alignment, akin to Google's Bard.
Ready to Tackle the Hard Problems:
In the [Alignment Lab AI ▷ #looking-for-work], @daydream.nation offered expertise in Python, Excel Data Modeling, and SQL, combined with a background in Philosophy and an interest in addressing consciousness with AI.
LAION Research Insights
LAION ▷
<ul> <li><strong>Cosine Annealing Takes a Backseat</strong>: @top_walk_town shared their surprise about a new report that challenges the effectiveness of cosine annealing, describing it as a 'roller coaster.' The report is accessible via [Notion](https://shengdinghu.notion.site/?utm_source=ainews&utm_medium=email&utm_campaign=ainews-the-core-skills-of-ai-engineering).</li> <li><strong>Research Lands on Blogs Over Journals</strong>: @chad_in_the_house and others find it noteworthy that significant research findings are often shared in blog posts rather than through traditional academic publishing due to the hassle with peer review processes.</li> <li><strong>Novel Architectures to Skip Traditional Publishing</strong>: @mkaic is considering releasing information on a novel architecture they are working on through a blog post, expressing frustration with the current state of academic publishing.</li> <li><strong>Low-Hanging Fruit in Machine Learning Research</strong>: @mkaic brought up how machine learning research is often just about applying well-known techniques to new datasets, which has become unexciting and crowds the landscape with incremental papers.</li> <li><strong>Industry Experience Over Academic Publications</strong>: @twoabove recounted how their practical achievements in data competitions and industry connections provided opportunities beyond what academic papers could offer, hinting at the diminishing impact of being published in top journals.</li> </ul> <p><strong>Links mentioned</strong>:</p> <ul> <li>[How Did Open Source Catch Up To OpenAI?](https://www.youtube.com/watch?v=PYZIOMvkUF8&utm_source=ainews&utm_medium=email&utm_campaign=ainews-the-core-skills-of-ai-engineering)</li> <li>[Notion – The all-in-one workspace for your notes, tasks, wikis, and databases](https://shengdinghu.notion.site/MiniCPM-Unveiling-the-Potential-of-End-side-Large-Language-Models-d4d3a8c426424654a4e80e42a711cb20?utm_source=ainews&utm_medium=email&utm_campaign=ainews-the-core-skills-of-ai-engineering)</li> </ul>ML Library in an HPC Environment like LUMI
- Activation Function Analysis and OpenAI's Mish Experiment: A discussion on activation functions like GeLU, ReLU, Mish, and TanhExp took place with insights shared regarding empirical testing. Legal concerns about training data transparency were also raised.
- Transformer++ and Mamba Models Examined: Questions arose about Mamba models compared to Transformers++ and Pythia, emphasizing the need for fair comparisons.
- Diverse Takes on Activation Functions Impact: Users discussed the subtle influences of activation functions on model performance, referencing empirical results.
- Legal Quandaries of Large Model Training: Concerns were raised about legal complications related to transparency in model training data sources.
LM Studio General Discussions
###LM Studio General Discussions
- Users in the general discussions channel of LM Studio raised various queries and discussions related to the capabilities and challenges of LM Studio.
- Topics included the learning curve for LLM creation, exploring LM Studio plugins, clarifying the capabilities of LM Studio, hardware-related queries, and model recall and context window exploration.
- The discussions provided insights into the complexities of working with LM Studio, the need for expertise in machine learning and PyTorch, considerations for improving speed with 70b models, and the importance of VRAM in running LLMs efficiently.
- Users also shared experiences with Docker, setup issues, and considerations for hardware upgrades. The community engaged in troubleshooting, sharing tips, and offering advice on optimizing performance and addressing technical challenges.
HuggingFace Reading Group
This section of the Discord channel highlights discussions related to the HuggingFace Reading Group. Topics include announcements for upcoming presentations on AI and law, engagement for future events, sharing resources for the Mamba paper, and troubleshooting issues with the Diffusers release. Users also engage in discussions about GPT models, tokenizers, and model performance evaluations. The group interacts in a collaborative and informative manner, sharing links to relevant resources and providing assistance to each other.
Discord Communities Highlights
- Project Showcased but Not Open Source: @sublimatorniq shared details about a project on socontextual.com which is not open source at the moment.
- Keen Anticipation for Project Release: Users @atomicspies and @mrdragonfox expressed admiration and anticipation for a showcased project, praising its utility in research over traditional methods.
- The Year-Long Journey to Perfection: @sublimatorniq anticipates that it will likely take a year to advance the project to where they want it to be.
- "LLaVA-1.6" Performance and YouTube Demo: @pradeep1148 linked to a YouTube video titled Trying LLaVA-1.6 on Colab, showcasing the capabilities of the LLaVA-1.6 version with improved reasoning and world knowledge.
- Discworld AI Fan Fiction Experiment: @caitlyntje created a fan fiction story titled "Sapient Contraptions" inspired by Sir Terry Pratchett, using open source AI LLM software like Mistral and Huggingface, and shared the story on Pastebin. @amagicalbook expressed interest in learning the process for their own story writing endeavors.
Troubleshooting CUDA and ImportError in Coding
<code>@ashpun</code> faced a <code>RuntimeError</code> related to a failed <code>inline_ext</code> build in CUDA kernel coding. The issue was resolved by <code>@marksaroufim</code> who identified a missing brace in the kernel code.#### After resolving the previous issue, an ImportError indicating a missing <code>GLIBCXX_3.4.32</code> version was encountered by <code>@ashpun</code>. The solution suggested involved running <code>conda update --all</code> and setting the <code>LD_LIBRARY_PATH</code> correctly.### Links mentioned: - How to Optimize a CUDA Matmul Kernel for cuBLAS-like Performance: a Worklog
Newsletter and Social Networks Links
In this section, there is a link to sign up for the newsletter at latent.space. Additionally, there are social network links to Twitter and the newsletter. The footer section mentions that the content is brought by Buttondown, an easy tool to create and expand newsletters.
FAQ
Q: What is LLaVA-1.6 and how does it compare to Gemini Pro?
A: LLaVA-1.6 is a model with enhanced reasoning, OCR capabilities, and world knowledge. A YouTube video demonstration suggests that LLaVA-1.6 outperforms Gemini Pro on several benchmarks.
Q: What is MiniCPM and why is it sparking interest?
A: MiniCPM is a new model showcased on Hugging Face. It has garnered interest due to its potential and performance, with discussions comparing it to models like Mistral and awaiting fine-tuning results.
Q: What are the discussions surrounding the application of ResNet growth techniques to LLMs?
A: Discussions have emerged regarding the application of successful ResNet growth techniques to LLMs, exemplified by Apple's Matroyshka Diffusion model. The entry of the new Miqu model on the Open LLM Leaderboard with notable scores has generated mixed reactions.
Q: How are quantization's impact on AI model performance being discussed in relation to miqu-70b?
A: Conversations around miqu-70b are raising questions about the potential effects of quantization on model performance aspects such as spelling accuracy, sparking debates on whether quantized models should become standard on specific platforms.
Q: What are the discussions around optimized tokenization in the engineering community?
A: The engineering community is discussing multilingual tokenizers and the potential limitations of a 32000-token vocabulary on models like LLaMA/mistral. Efforts to adapt LLaMA models for specific languages, such as VinaLLaMA for Vietnamese and Alpaca for Chinese, indicate progress in model internationalization.
Q: What legal concerns were raised in discussions around activation functions and training data transparency?
A: During discussions on activation functions like GeLU, ReLU, Mish, and TanhExp, legal concerns regarding training data transparency and empirical testing were also raised, indicating a focus on legal complexities within AI engineering communities.
Get your own AI Agent Today
Thousands of businesses worldwide are using Chaindesk Generative
AI platform.
Don't get left behind - start building your
own custom AI chatbot now!