[AINews] Fixing Gemma • ButtondownTwitterTwitter
Chapters
Fixing Gemma
High Level Discord Summaries
LlamaIndex Discord Summary
Alignment Lab AI Discord Summary
OpenAI API Discussions
LM Studio Models Discussion Chat
Nous Research AI - Interesting Links
AI Discussions in LAION Channel
LAION Research and Discussions
HuggingFace NLP
Few-Shot Versus Zero-Shot Performance Anomalies, Optical Digital Computing, Gemini 1.5 Report Overview, Yi Tech Report's Filter Approach
Discussions and Updates
OpenRouter Announcements and App Showcase
Innovative Training with the German Orca Dataset
Tackling AI Hallucinations and Gemma Enhancements
Chunk
Fixing Gemma
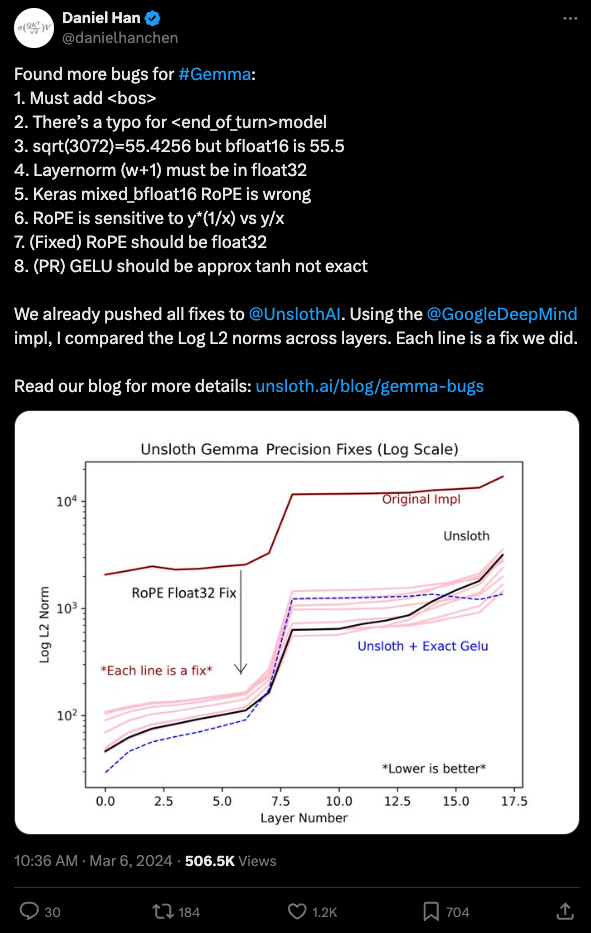
The Gemma model, recently released by Google, was known to be unstable for finetuning. Daniel Han from Unsloth received recognition for fixing 8 bugs in the implementation. The bugs were detailed in a thread and blog post, with Hacker News commentary and Google Colab available for further information. The Gemma model was found to have subtle numerical precision issues that require extreme attention to detail to notice.
High Level Discord Summaries
Unsloth AI (Daniel Han) Discord Summary
- Finetuning Frustrations and Triumphs: Challenges with special tokens and model loading after finetuning Gemma were highlighted, with recommendations for potential fixes. The community celebrated the implementation of multi-GPU support and a new FSDP + QLoRA system for training 70B models on gaming GPUs.
- Unsloth Giveaways and Growth: Ghost 7B v0.9.1 advancements, speedups, and memory reductions during LLM fine-tuning demonstrated Unsloth AI's optimizations. Knowledge sharing on Kaggle, AI2 Incubator's contributions, and updates and insights from the community contributed to the collaborative spirit.
- Boosting Productivity with Unsloth AI: Ghost 7B v0.9.1's ranking on VMLU's leaderboard, success stories from users, and advancements in reasoning and language showcased efficiencies during LLM fine-tuning.
- Celebrating AI Contributions and Cutting-edge Updates: Updates on bitsandbytes release and AI compute provision, along with discussions on OpenAI’s transparency and advancements highlighted community contributions and progress.
- Welcoming Winds and Gear for Growth: New member orientations, feature suggestions, acknowledgments of Galore advancements, and shared projects like GEAR demonstrated the community's forward-looking initiatives.
OpenAI Discord Summary
- Claude Edges Out GPT-4 in Coding Prowess: Claude Opus' performance in coding tasks over GPT-4, AI consciousness debates, bug workarounds, suggestions for improving ChatGPT's memory recall, and techniques for output consistency across custom models were discussed.
LM Studio Discord Summary
- Model Selection and Compatibility: Discussions on Mistral and Mixtral models, Gemma models' issues, alternatives like Yi-34b, power and cooling efficiency, suggestions for LM Studio feature enhancements, and ROCm compatibility concerns, including solutions for diverse operating systems, were explored.
- GEMMA Models’ Quirks Confirmed: User reports of technical issues persisting with Gemma models in LM Studio, even after custom quantized versions' release, led to suggestions for alternatives like Yi-34b.
- Explorations in Power Efficiency for LLM Setups: Engagements around high-end GPU power consumption, CPU performance, efficient RAM setups, LM Studio feature requests, and ROCM readiness on various operating systems were prominent topics.
- Desire for Improved LM Studio Features: Feature enhancement requests, discussions on Rocm compatibility across operating systems, optimizations for running models on Windows, and agent loop concerns with CrewAi and AutoGen for bot integration were detailed.
LlamaIndex Discord Summary
Innovative Code Splitting with CodeHierarchyNodeParser
Users in the LlamaIndex guild discussed the use of CodeHierarchyNodeParser for splitting large code files into hierarchies, potentially enhancing RAG/agent performance. The approach has been shared on Twitter.
AI Chatbot Challenges and Cosine Similarity Clarifications
A user sought advice on creating a RAG chatbot using LlamaIndex, citing the Ensemble Retriever document, while another user clarified the range of cosine similarity, which includes negative values and its implication for similarity score cutoffs in a query engine, referencing Wikipedia.
Handling Ingestion Pipeline Duplication and Conda Install Issues
Discussions highlighted solutions for ingestion pipelines processing duplicates, solved by using filename_as_id=True, while another user reported on and sought help with resolving Conda installation conflicts involving version mismatches and modules not found post-upgrade.
Query Pipeline Storage Queries and PDF Parsing with LlamaParse
One user inquired about saving pipeline outputs, questioning the feasibility of using Pydantic objects, and another shared informational resources on PDF parsing using LlamaIndex's LlamaParse service through a YouTube video.
Engaging Community with User Surveys and AI-enhanced Browser Automation
LlamaIndex is conducting a 3-minute user survey, found here, to gather user feedback for improvements while also discussing LaVague, a project by @dhuynh95 utilizing RAG and MistralAI to aid in creating Selenium code from user queries, detailed in this post.
Alignment Lab AI Discord Summary
Engineers on Alignment Lab AI Discord debated strategies to reduce AI hallucinations without reaching a consensus. The use of Claude to generate mermaid graphs and the arrival of Gemma-7b with enhanced features were highlighted. Discussions also centered around the comparison of Gemma and Mistral models, community collaboration in coding, and speculations on Google's potential dominance in AI. The diverse conversations reflected on advancements and challenges in the AI field.
OpenAI API Discussions
Efficient Prompt Engineering with GPT
- @eskcanta articulated the basic steps for creating efficient prompts, outlining the importance of clarity, language proficiency, and instructing the model with specifics. They advised to avoid typos, grammar mistakes, and to communicate in any language well understood by both the user and the AI.
Keeping Custom GPT Outputs Consistent
- According to @darthgustav., employing an output template with variable names that encode a summary of the instructions can help maintain consistent output from custom GPT prompts.
Professional Vocabulary Expansion Challenge
- @ericplayz sought assistance in rewriting a paragraph with professional vocabulary while keeping the word count; @eskcanta shared an attempted solution and prompted for feedback to assess if the needs were met. The guidance included ensuring that the rewritten text in Romanian maintains length, details, and appropriate tone.
JSON Formatting in GPT-4 Discussions
- @dellgenius inquired about the use of JSON formatting for organizing responses; @aminelg confirmed its utility for structured data, and @eskcanta answered questions about creating UI elements and the varying capabilities of the AI model. There was a focus on how GPT models can aid in designing UI elements, provided the AI has been trained on the relevant data or tools.
Requests for Assistance Using ChatGPT API
- Users @youri_k and @levidog requested help with making ChatGPT remember chat history and extracting questions from an assignment document, respectively. They received guidance from @eskcanta, who suggested using summaries for history retention and cautioned that the models are not designed to aid with homework, which might lead to inconsistent results.
LM Studio Models Discussion Chat
GEMMA Models Puzzlement
- @boting_0215 encountered issues with all Gemma models not being usable. @fabguy confirmed that only a few Gemma quants work, and these are custom quantized versions by the team, pinpointing a potential issue either with LM Studio or the Gemma model.
Troubleshooting Gemma Load Error
- @honeylaker_62748_43426 received an error when loading a 7B Gemma model, and @heyitsyorkie affirmed that Gemma models frequently encounter issues, with some quants known to be broken.
Searching for the Elusive Slider
- @jo_vii sought advice for models suitable for an M2 Max Apple Metal and @fabguy suggested using a DeepSeek Coder Q4 or Q5 to leave room for other processes.
Model Upload Confusion
- @anand_04625 couldn't find the file upload button for the Phi model in LM Studio, and @heyitsyorkie clarified that model file uploads are not supported.
Awaiting Starcoder 2 Update
- @rexeh was looking for alternatives to Starcoder 2 on lm studio for ROCm users, and @heyitsyorkie indicated that support for Starcoder 2 will come in the future, while currently recommend building llama.cpp independently.
Nous Research AI - Interesting Links
WildBench Benchmark for Instruction Generation:
- Shared a link to the WildBench benchmark on Hugging Face, which could be seen as a call for a new type of benchmark to assess instruction generation in AI.
Bonito for Synthetic Dataset Creation:
- Introduced Bonito, a model for converting unannotated text into task-specific training datasets, which has implications for both pretrained and instruction-tuned language models.
Lex Fridman Tweets About AI and Power:
- Brought attention to a tweet by Lex Fridman, potentially covering AI's intersection with power and social dynamics.
A Philosophically Optimistic AI Server:
- Shared an invitation to a Discord server dedicated to discussions on AI, philosophy, technology, and an optimistic future, aiming to critique AI pessimism.
AI Discussions in LAION Channel
The LAION channel is abuzz with various discussions related to AI technology and its implications. Members express disdain for ineffective tools like Glaze and Nightshade, questioning their claimed content safeguarding capabilities. There are debates on exaggerated threats posed by AI 'worms' and misleading articles on AI's impact. Other topics include the effectiveness of LLMs in creative writing, ethics of publishing, and anticipation for OpenAI's SD3 release. Critiques of misinformation in academic journals, mentions of technological advancements like ultra-low power AI chips, and discussions on AI's impact on creativity and employment are also part of the ongoing conversations.
LAION Research and Discussions
Users in the LAION research group discussed various topics related to AI models. Some expressed concerns about the quality of high-resolution models and the limitations of smaller models. Others proposed ideas for advanced video scripting and explored the CogView3 framework. Conversations also touched upon the efficiency of models like ELLA and SD3, speculating on performance and scalability. Links shared included resources on equipment diffusion models, running large LLMs locally, and more.
HuggingFace NLP
Links mentioned:
- PyTorch: Fine Tuning GPT2 For QuestionAnswering: Explore and run machine learning code with Kaggle Notebooks | Using data from No attached data sources
- Overview: no description found
- wav2vec2-codebook-indices/scripts/helpers/w2v2_codebook.py at master · fauxneticien/wav2vec2-codebook-indices: Contribute to fauxneticien/wav2vec2-codebook-indices development by creating an account on GitHub
- GitHub - huggingface/lighteval: LightEval is a lightweight LLM evaluation suite that Hugging Face has been using internally with the recently released LLM data processing library datatrove and LLM training library nanotron: LightEval is a lightweight LLM evaluation suite that Hugging Face has been using internally with the recently released LLM data processing library datatrove and LLM training library nanotron
Few-Shot Versus Zero-Shot Performance Anomalies, Optical Digital Computing, Gemini 1.5 Report Overview, Yi Tech Report's Filter Approach
Few-Shot Versus Zero-Shot Performance Anomalies: @paganpegasus observed that zero-shot performance on the MMLU benchmark could be better than few-shot performance for some models. Possible reasons discussed were the distraction of additional context for smaller models and the impact of testing performance with varying shot numbers.
Frontiers in Optical Digital Computing: @ai_waifu highlighted a paper exploring all-optical digital computing and memory, discussing topics like semiconductors and its implications on manufacturing.
Gemini 1.5 Report Overview Provided: @xylthixlm announced the release of the Gemini 1.5 report without substantial technical details. @main.ai later shared insights into the new content of the report.
Yi Tech Report's Double Wikipedia Filtering Approach: @maxmatical raised a question about Yi tech report's approach of filtering Wikipedia content twice. @thedeviouspanda suggested similarities to the use of light and heavy rankers in ranking pipelines, with each step filtering more intensively.
Discussions and Updates
The section provides updates and discussions from various Discord channels related to AI and machine learning. It includes conversations about workflow optimization with AI, community support for newcomers in NLP, technical clarifications during live club sessions, visualization tools for GPT models, and proposed future session topics on decentralized and distributed AI applications. Additionally, there are discussions on Elon Musk's open-source announcement, Cohere's Command-R model, Mistral's open-source commitment, GPT-4's ability to play Doom, and drama over Inflection AI's chatbot model. The section also covers humorous interactions such as creating AI celebrities-themed memes based on characters from Dune, discussions on podcast episodes related to reinforcement learning, and exploring RLHF, PPO, and Expert Iteration for improving LLM reasoning capabilities.
OpenRouter Announcements and App Showcase
OpenRouter Announcements:
- New Speed Champion Mistral 7b 0.2: @alexatallah introduced Mistral 7b 0.2 with significant speed boosts of 10x and 20x for short and long outputs respectively, along with a context window of 32k.
- Gemma Nitro hits the market: Gemma Nitro, a cost-effective and high-speed model, offers speeds of over 600+ tokens per second at $0.1 per million tokens.
- Sneak peek tweet?: @alexatallah shared a mysterious Twitter link without context.
- OpenRouter flaunts no spending limits: Users are informed of a policy change allowing for no $ usage limits on the platform to encourage more usage.
OpenRouter App Showcase:
- Claude 3 Function Calling Made Easy: User @thevatsalsagalni introduced a function calling library for the Claude 3 model family, supporting Pydantic function schemas and open for exploration and contribution on GitHub.
Link to Gemma Nitro details Link to the Claude 3 library on GitHub
Innovative Training with the German Orca Dataset
Innovative Training with the German Orca Dataset: @johannhartmann explained their method of using a German translation of the slim orca dataset to train and merge models like Mistral. They use the SPIN-like method - taking the output of one model as input for the next - and track the relationships between models through the dataset, monitoring how training affects verbosity and answer quality.
Tackling AI Hallucinations and Gemma Enhancements
- Tackling Hallucinations in AI: Discussions on reducing hallucinations in AI based on a technical report.
- Strategies for Reducing AI Hallucinations: Speculations on reducing hallucinations through RAG or fine-tuning data.
- Fine-Tuning Data's Role in Minimizing Hallucinations: Consideration of using a validation set and rewriting repetitive responses.
- Latest from LAION: Sharing of a Twitter link by spirit_from_germany without context.
- Search for Efficient Small Embedding Models: Inquiry about small embedding models supporting long input lengths.
- Claude's Proficiency at Diagramming Code: Highlighting Claude's ability to convert code bases into mermaid graphs.
- Visualizing Code with Mermaid: Practical example of using mermaid graph syntax for code visualization.
Chunk
In this section, we continue to explore the content of the web page, focusing on the next chunk of information. Let's delve into the details provided within this portion of the page.
FAQ
Q: What issues were identified with the Gemma model released by Google?
A: The Gemma model was found to be unstable for finetuning and had subtle numerical precision issues that required extreme attention to detail to notice.
Q: Who received recognition for fixing 8 bugs in the Gemma model implementation?
A: Daniel Han from Unsloth received recognition for fixing 8 bugs in the Gemma model implementation.
Q: What were some of the challenges highlighted in the finetuning process of the Gemma model?
A: Challenges with special tokens and model loading after finetuning Gemma were highlighted, with recommendations for potential fixes.
Q: What improvements were celebrated in the Unsloth AI community related to model training?
A: The community celebrated the implementation of multi-GPU support and a new FSDP + QLoRA system for training 70B models on gaming GPUs.
Q: What were some key advancements showcased in Ghost 7B v0.9.1 by Unsloth AI?
A: Advancements, speedups, and memory reductions during LLM fine-tuning were demonstrated in Ghost 7B v0.9.1 by Unsloth AI.
Q: What were the topics discussed in the LM Studio Discord summaries?
A: Discussions in the LM Studio Discord summaries covered model issues, power efficiency in LLM setups, feature enhancement requests, and ROCm compatibility concerns.
Q: What was the purpose of using CodeHierarchyNodeParser discussed by users in the LlamaIndex guild?
A: Users discussed using CodeHierarchyNodeParser for splitting large code files into hierarchies, potentially enhancing RAG/agent performance.
Q: What topics were addressed in the AI Chatbot Challenges and Cosine Similarity Clarifications?
A: Users sought advice on creating a RAG chatbot using LlamaIndex and clarified the range of cosine similarity, including its implications for similarity score cutoffs.
Q: What were some solutions discussed for Conda installation conflicts reported by users?
A: Discussion highlighted solutions such as using 'filename_as_id=True' for ingestion pipeline duplicates and resolving version mismatches and module issues in Conda installations.
Q: What were users inquiring about regarding pipeline storage, PDF parsing, and automation with LlamaIndex services?
A: Users inquired about saving pipeline outputs, using Pydantic objects, and engaging in user surveys and AI-enhanced browser automation with LlamaIndex services.
Get your own AI Agent Today
Thousands of businesses worldwide are using Chaindesk Generative
AI platform.
Don't get left behind - start building your
own custom AI chatbot now!